支持向量机的代价函数
$$
J(\theta) = \min_{\theta} C\sum_{i=1}^m[y^{(i)}cost_1(\theta^Tx^{(i)}) + (1-y^{(i)})cost_0(\theta^Tx^{(i)})] + \frac{1}{2}\sum_{i=1}^n\theta_j^{2}
$$
C 可以看作 $\frac{1}{\lambda}$
支持向量机的作用
- 人们有时将支持向量机看作是大间距分类器
- 支持向量机能够努力的将正样本和负样本用最大的间距分开。这也是支持向量机具有鲁棒性的原因,鲁棒是Robust的音译,也就是健壮和强壮的意思。
- 支持向量机(SVM)实际上是一种凸优化问题,因此它总是能找到全局最小值或者接近它的值从而不用担心局部最优
关于内积和范数
1. 内积:设有n维向量
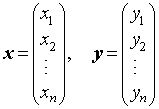
令 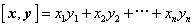 ,
,
则称[x,y]为向量x与y的内积。
2. 范数:称 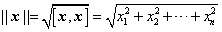 为向量x的范数(或长度)。
为向量x的范数(或长度)。
支持向量机产生大间距分类的原因
由内积和范数引起变化,具体先不写。。。
核函数
公式
$$
exp(-\frac{||x-l^{i}||^2}{2\sigma^2})
$$
目的
使用核函数构造复杂的非线性分类器,能够根据数据的相似与否定义许多新的特征值
相似度函数就是核函数就是高斯核函数,$\sigma$ 是高斯核函数的参数
我们通过标记点和核函数来定义新的特征变量从而训练复杂的非线性边界
如何使用
我们通过核函数能够得到
如何选取标记点
每一个标记点的位置都与样本点的位置精确对应,选出 $m$ 个标记点。这样就说明特征函数基本上是在描述每一个样本距离样本集中其他样本的距离
支持向量机如何通过核函数有效的学习复杂非线性函数
如果我们要进行预测,首先我们需要计算特征向量 $f_{(m+1)×1}$ ,内部值都是 传入 $x$ 与 标记点 通过核函数 与m个样本点进行相似度比较产出的。
我们再使用参数转置乘特征向量: $\theta^Tf = \theta_0f_0 + \theta_1f_1 + \theta_2f_2 + ……+ \theta_mf_m$
如果结果 大于等于零,预测结果为 1。
但是我们怎么获得参数 $\theta$ 的值,我们通过最小化下式就能得到支持向量机的参数
$$
J(\theta) = \min_{\theta} C\sum_{i=1}^m[y^{(i)}cost_1(\theta^Tf^{(i)}) + (1-y^{(i)})cost_0(\theta^Tf^{(i)})] + \frac{1}{2}\sum_{i=1}^n\theta_j^{2}
$$
这里的 $n = m$ ,这里我们仍然不对 $\theta_0$ 做正则化处理
最后的 $\sum_{i=1}^n\theta_j^{2}$ 还能够被写为 $\theta^T\theta$ 或是别的比如 $\theta^TM\theta$ ,这取决于我们使用的是什么核函数,这能够使支持向量机更有效率的运行,这样修改能够适应超大的训练集,那时 求解m维参数的成本会非常高,主要为了计算效率。
核函数虽然也能用在逻辑回归上,但是它毕竟是为支持向量机开发的,用在逻辑回归上会十分缓慢。
使用支持向量机时,怎么选择支持向量机里的参数
参数 $C$
在使用支持向量机时,其中一个要选择的事情是目标函数中的参数 $C$ 。
我们知道 $C$ 的作用类似于 $\frac{1}{\lambda}$ 。
如果使用较大的 $C$ ,这意味着我们没有使用正则化,这可能使我们可能得到一个低偏差高方差的模型。
如果使用较小的 $C$ ,这相当于我们在逻辑回归中用了一个大的 $\lambda$,这可能使我们可能得到一个高偏差低方差的模型。
高斯核函数中的参数 $\sigma^2$
当 $\sigma^2$ 偏大时,由核函数得到的相似度会变化的很平缓,这会给模型带来较高的偏差和较低的方差。
当 $\sigma^2$ 偏小时,由核函数得到的相似度会变化的很剧烈,会有较大斜率和较大的导数,这会给模型带来较低的偏差和较高的方差。
运用SVM时的一些细节
使用不带有核函数的支持向量机就叫做线核的SVM,即没有 $f$ ,你可以把它想象为给了你一个线性分类器
线核SVM
如果有大量的特征值(N很大),且训练的样本数很小(M很小),那么是不会去想着拟合拟合一个非常复杂的非线性函数的,因为没有足够多的数据很有可能过度拟合。
高斯核函数
如果有少量的特征值(N很小),且训练的样本数很大(M很大),
提供核函数
高斯核函数和线性核函数是最普遍的核函数,
注意事项:如果你有大小不一样的特征变量,为了不使间距被大型特征操控(小的特征都被忽略掉),在使用高斯核函数前最好将这些特征变量的大小按比例归一化。
warning:所有的核函数都已经满足一个技术条件,它叫做莫塞尔定理。
吴恩达很少很少很少使用其他核函数,
多类分类(K分类)中如何使用支持向量机
现成的多类分类的函数包,
逻辑回归算法于支持向量机的选择
$n>=m$ 逻辑回归或者线核SVM,因为没有更好更多的数据拟合复杂的非线性函数
$n<=m$ 高斯SVM
$n<<=m$ 增加或者创建更多的特征变量,然后使用逻辑回归或者线核SVM
为什么不使用神经网络
训练起来会特别的慢
最后
算法确实很重要,但更重要的是我们有多少数据,我们是否擅长做误差分析和诊断学习算法来指出设定新的特征变量,或找出其他能够决定我们学习算法的变量等方面,通常这些方面会比我们使用逻辑回归还是SVM这方面更加重要

